
ああいうのとか
投稿日:
まろ茶の人のとりとめのないブログもどき
サーバー作業の関係もすっかりローカルのVScodeからリモートSSHで行う環境に慣れきってしまい、徐々にputtyとかの普通のSSH端末ソフトを使わなくなってきた。しかし、たまーにROOTで作業をしたいとかApache Userでコンテンツを直接修正したい時などはputtyなどを使用していたが、これもいっそのことVScodeをSSH端末代わりに使用してしまってはどうだろうか?との思いになり、しばらく使ってみたらいきなり躓いた。
VScodeではemacsキーバインドのプラグイン(Awesome Emacs Keymap)を使用しているが、VScodeのリモートSSHでコマンドラインを使用して、他のユーザーにsuしてエディタを使用する場合、パーミッションの関係でVScodeは使用できないのでリモートのemacs系エディタを使うことになる。そこで編集を終了して「いざエディタ終了」と「Ctrl+X、Ctrl+C」と打つと、当のリモートのemacsだけでなく、VScodeもこのキー操作を拾ってしまい、VScodeも終了してしまうという問題が起こった。
考えた挙句、しばらくは「M-x kill-emacs」と手動で打って終わらせることは可能だったが、これではどう考えても不便。。。
というか、よく考えたらキーバインドを弄って「 Ctrl+X、Ctrl+C 」を解除すれば良いじゃない?ということで、探してみてもキーマップのファイルが見つからない。
調べた結果、Windows版だと左下の歯車マークの設定から、「キーボードショートカット」を選ぶとよいということで、「Close Window」に割り当てられた「 Ctrl+X、Ctrl+C 」を解除することで、リモートemacsでもストレスなく使用できるようになった。
・・・という覚書でした。
djangoを通じてWEBアプリの勉強中。ポータルサイトのdjangoアプリで一通り遊び尽くしたところで、今度はフロント側の見た目やスクリプトに手を付け始めた。
今まではサイトの情報をそのままコピペするようにサイトを作ってきたので、その辺のメカニズムについて勉強を始めた所。今までHTMLとかCSSは必要に応じて編集してきたが、知識は初期のHTML3?あたりで止っているので、そのあたりも昨今のHTML5まで追いつけたら良いなぁ位には考えている。
BootstrapでレスポンシブルなWEBサイトを・・・と分かったような分かってないような事を書いてみたが、使っていくと結構便利で、あんまり考えなくても一応ちゃんとしたサイトが作ることが出来る(本サイトのポータルもdjango+Bootstrap)。しかし、いろんなサイトの情報をつまみ食いしながらゴチャゴチャやってきたら、非常にごちゃごちゃのHTMLソースが出来上がってしまった。
例えば、下記カード型サイドメニューの一部だが、クラスタグのカタマリのようになってしまう。
<div class="container-fluid">
<div class="row justify-content-md-center">
<div class="col-md-2 px-1">
<!-- 右側サイドバー -->
<div class="card px-0 mx-0 my-2">
<div class="card-body">
<h4 class="card-title btn rounded-pill btn-outline-dark">Side Menu</h4>
<ul class="list-group list-group-flush">
<li class="list-group-item">
・・・・・・
そもそも、HTMLとCSSに分かれたのって、文書と見た目の装飾を分けるのが目的で、HTMLの新しくなるにつれて、ボールドとかイタリックとか文字サイズの直接変更みたいなのは削除されてきたように思うのだが、昨日今日勉強し始めた素人的な感想だが、一応昔からHTMLには接してきてその進化も遠巻きに見てきたので、HTMLはあくまでも文書とその構造を定義するもので、見た目や表現はCSSの仕事という認識。
Bootstrapは確かに便利でいろんなパーツが揃っているが、こうもクラスタグで文書の見た目についての情報をベタベタ貼付けていると、何か本末転倒のような気がするのもあるかなーと思う。
確かに汎用性があるのは良いのだが、もっとCSSの方でスッキリ纏められないものかと、調べてみると、世の中考える人は多いもので、SASSというツールに辿りついた。これはCSSのプリプロセッサのようなもので、CSSだけでは手が届かなかった構造化したスタイルシートを定義して、CSSにコンパイルするツール。
これを使えば例えば 「card-bodyクラスのブロックに含まれるh4ヘッダはこのスタイル」と決められる。またdivを使用せずに「cardクラスのブロックに含まれるsectionというブロックはcard-bodyのスタイルを持つ」みたいな感じでdivを多用せずに意味のあるブロックで文書を構成することが出来る。
.cardclass {
@extend .card, .px-0, .mx-0, .my-2;
section {
@extend .card-body;
h4 {
@extend .card-title, .btn, .rounded-pill, .btn-outline-dark;
}
ul {
@extend .list-group, .list-group-flush;
li {
@extend .list-group-item;
}
}
}
}
と定義出来、上のHTMLも
<div class="container-fluid">
<div class="row justify-content-md-center">
<div class="col-md-2 px-1">
<!-- 右側サイドバー -->
<div class="cardclass">
<section>
<h4>Side Menu</h4>
<ul>
<li>
・・・・・・
のように長々としたクラスタグを書かずにスッキリさせることが出来る。
久々にこの手の勉強を始めて間もないので、こういう考え方で良いのかどうか分からないが、少なくとも文書の構造を定義するHTMLの考え方はこうじゃないかなと、思う所。あとCSSファイルのサイズの肥大化でページの読み込み速度の話もあるかも知れないが、とりあえずは今はそっちは考えないとする。
と、まぁそんな感じで、自サイトを使用して色々試しているが、今日もブラウザキャッシュの罠にハマって半日ほど無駄にしてしまった。。テスト環境と本番環境で同じファイルなのに本番環境のみ一部のクラスタグの部分が反映されないとか・・・これもキャッシュだったとは。とりあえず難しいことは考えずにこまめにキャッシュクリアが大事です。
本番環境にはSassコンパイラ入れてなかったので、いろいろ大変なことになっていた。
最近たまに書くというとこればかりの話になっているが、その割には一向に進まない・・・
djangoへの実装だが、今回はデータベースを使用するわけでもないテストページなので新たにアプリケーションを追加することなく、ポータルのトップページにコッソリぶら下げることとする。(とりあえずログインユーザーのみのアクセス制限は掛ける予定として)
まずはurls.pyへのページ追加
app_name = 'top'
urlpatterns = [
path('', views.IndexView.as_view(), name='index'),
path('iplog/', views.BadIPView.as_view(), name='badip'),
path('ipsum/', views.IpSumView.as_view(), name='iplog'),
]
indexは通常のポータルページで、今回 iplogとbadipという名前のページを追加する。iplogが不正アクセスの疑いのある(何回もログイン失敗を繰り返す輩)のIPアドレスとアクセス回数のリスト、badipがそのIPアドレスのアクセス履歴を表示するページ。
どちらのクラスもデータベースを使用せず、サーバー側のデータをリスト化して参照するので、まずはIpSumViewクラスから。
class IpSumView(generic.ListView):
template_name = 'top/ipsumlist.html'
context_object_name = 'ipaddress_records'
queryset = None
paginate_by_default = 20
form1 = None
form_initial = {}
template_nameは使用するテンプレートのパス名、context_object_nameはテンプレートで使用するリスト。querysetは通常であればデータベースの問い合わせとして、モデルオブジェクトとの接続を行なうが、ここではNoneとしてメソッドのget_queryset()をオーバーライドして先のアクセス解析関数からの戻り値のリストとして返す
def get_queryset(self):
"""URL引数を取り出すサンプルとデータベースの代わりに動的にリストを作成する
"""
days = int(self.request.GET.get('days', 1))
max = int(self.request.GET.get('count', 1))
srt = self.request.GET.get('srt', 'count')
src = self.request.GET.get('src', 'bt')
return get_login_report(get_datetime_hours_ago(days * 24), get_datetime_hours_ago(0), max, src, srt)
実際はフォームのためのパラメータセットなどがあるが省略。
リクエストGETでパラメータを設定するが、パラメータがない場合の初期値を取るため上記のような書き方となっている。get_login_reportがアクセス集計関数
def get_login_report(st, ed, max = 1, src = 'bt', srt = 'count'):
iplist = {}
#hists = get_login_history(st, ed)
list1 = get_django_loginfails(None, st, ed) if src != 'wp' else []
list2 = get_wp_loginfails(st, ed) if src != 'dj' else []
hists = list1 + list2
blist = get_blocklist()
for adr in map(lambda x: x['address'], hists):
iplist[adr] = iplist[adr] + 1 if adr in iplist.keys() else 1
retv = [{'address':adr, 'count': cnt} for adr, cnt in iplist.items() if cnt >= max and adr not in blist]
if srt == 'count':
retv.sort(key = lambda x: x['count'], reverse=True)
else:
retv.sort(key = lambda x: hash(x['address']), reverse=True)
return retv
wordpressのログイン履歴データベースからのリストと、djangoポータルページへの履歴を合せて、アクセス回数ごとのリストに変換。指定回数以上アクセスした対象を返す関数となっている。
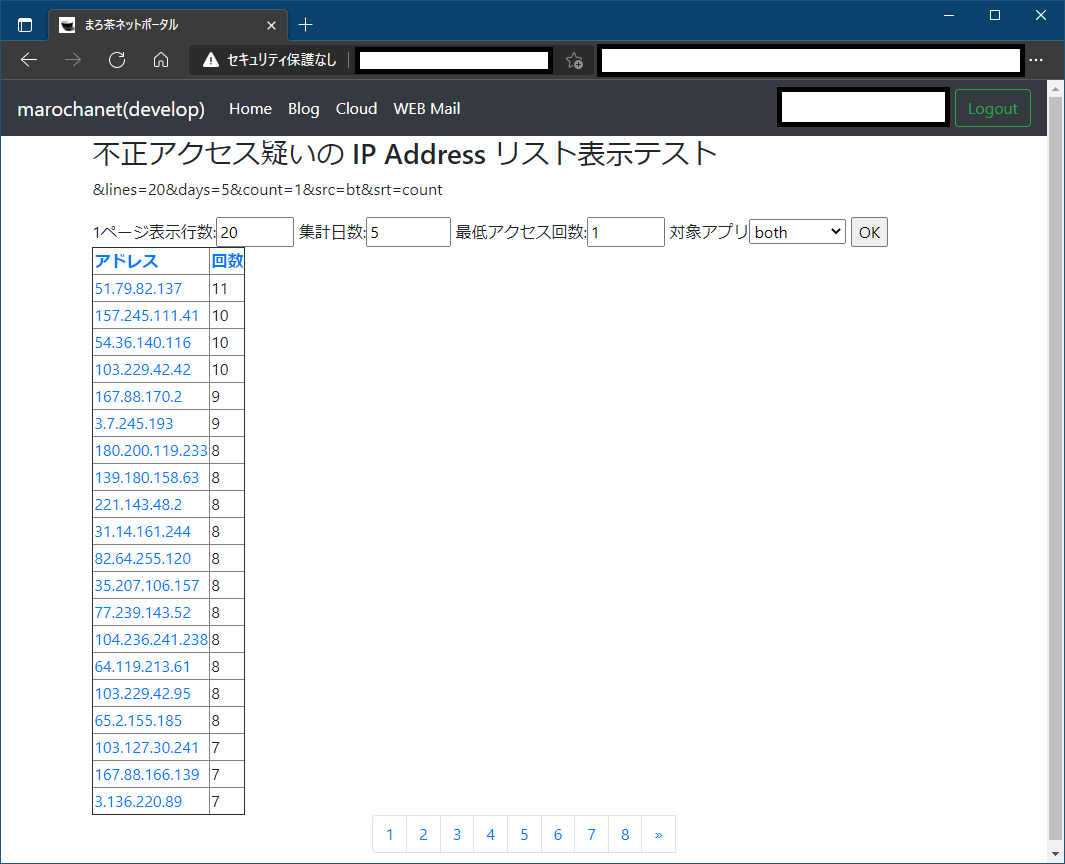
左がとりあえずの完成形となる。BootstrapのNavibar以外は装飾無しの素のHTMLなので飾りっ気一切無し。この辺の見栄え関連は次回以降勉強していくことにする。
めっちゃくちゃ端折った感じで完成してますが、所詮覚え書きなので、ここまでの作り込みに関して気が付いたときに勘所とかを追記していこうと思います。
いよいよ集計アプリをdjango WEBアプリに実装。その前に、WordpressのLoginHistoryプラグインのログも拝借するコードを追加
from datetime import datetime, timezone, timedelta, tzinfo
import MySQLdb
tz_jst = timezone(timedelta(hours=9), name='JST')
def get_wp_loginfails(st, ed, address=None):
"""
wordpressのデータベースから認証履歴のレポートを返す(要:プラグイン User Login History)
[引数] st : レポート対象の開始日時
ed : レポート対象の終了日時
address : レポート対象のIPアドレスオブジェクト(Noneの場合は全て)サブネット検索対応
"""
user = '<USER>'
passwd = '<passwork>'
host = 'localhost'
db='<dbname>'
rows = None
with MySQLdb.connect(user = user, passwd = passwd, host = host, db = db) as conn:
with conn.cursor() as cur:
(stat1, ed1) = (x.astimezone(timezone.utc).replace(tzinfo=None) for x in (st, ed))
sql = 'select username, time_login, ip_address, login_status from wp_fa_user_logins'\
' where time_login > %s and time_login < %s' #and login_status = %s'
cur.execute(sql,(stat1, ed1)) # <> 'login'
rows = cur.fetchall()
# rows 集計
rows = rows if address is None else [row for row in rows if ipv4adrset(row[2]) == address]
retlist = [
{
'name':row[0],
'datetime':row[1].replace(tzinfo=timezone.utc).astimezone(tz_jst),
'address':ipv4adrset(row[2]),
'status':False if row[3]=='fail' else True,
'source':'wordpress',
} for row in rows]
return retlist
なんやらいろいろゴチャゴチャやってるけど、とりあえずmysqlに貯め込んでいるログイン情報を指定期間分取り出してくる。
前回の記事でパイプ接続したプロセスをmapのまま返すとプロセスが終らないまま関数から帰ってきてしまうので、気持ち悪いからlist関数を使ったが、
bipset = list(map(lambda x: ipv4adrset(x.decode('UTF-8').rstrip('\n')), proc.stdout))
↓
bipset = [ipv4adrset(x.decode('UTF-8').rstrip('\n')) for x in proc.stdout]
の様に、わざわざmap使うより、下のようにリスト内包表記で直接リストを返すような仕組みを用いた方がスマートな気がした。とくに今回のようにmap直後にlistするような使い方の場合特に。
mapやfilterはイテレータなので直後にforなどのループ処理を行なう場合に適しており、リストそのものが欲しいときにはmapを使わずに[リスト内包表記]をするのが良いきがする。リスト内包表記やlist式のリスト生成では各項目の変換式(関数)が一度に使用され結果のリストが返されるが、イテレータでは生成段階では変換式(関数)は実行されず、for文など繰返し処理が行なわれる時に一つずつ実行されることになる。
たとえばファイルを読み込み関数があったとして、オープンしたファイルハンドルに対して読み出して検索や加工をする処理の結果をイテレータとして返してしまうと、関数からリターンした段階でファイルを閉じると、そのイテレータからは読み出せないという結果になる。
ということでその場合は、リストとして返す関数が正解となる。
あと、イテレータからリストに変換するときに一度繰返し処理が行なわれるという考え方からすると、for文に使用する前にリストに変換するのは効率が悪く。動作速度的にも不利になるようなので、そういう観点で使い分けていく目安になるのではないかと思う。
次に、ログファイルの解析部分。これも前回記事で、djangoの認証バックエンドをチョットいじって、ログイン失敗のログを残せるようにしたので、ここではそれを検出してリストとして返すこととする。ログファイルはApacheユーザーに読取り権限があるので、そのまま読見込めばいい。ただし、/var/logに保存している場合など、logrotateの処理が行なわれる場合それも追跡して行ないたい。また古いログはrotate時にgzip圧縮されるのでこれにも対応したい。
from blocklib import ipv4adrset
import os, glob, gzip
logger = getLogger(__name__)
import re, json
# djangoのアクセスログ(json形式)を読み込に認証履歴のレポートを返す
# 認証履歴のログはdjango認証バックエンドを継承して認証時のログ出力機能を追加したもの
# [引数]djlog : 解析するアクセスログ(json形式)をフルパスで与える(gzipもOK)
# Noneの場合は、デフォルト django_log_json を使用(logorotateされたものも含み全てを読み込む)
# st : レポート対象の開始日時(logrotateされたファイルはこの日時より新しいものを読み込み対象とする)
# ed : レポート対象の終了日時
# address : レポート対象のIPアドレスオブジェクト(Noneの場合は全て)サブネット検索対応
def get_django_loginfails(djlog, st, ed, address=None):
if djlog is not None:
djlogs = [djlog]
else:
djlogs = [x for x in glob.glob(django_log_json + '*') if re.match('.*(log|gz|[0-9])',x) and os.path.getmtime(x) > st.timestamp()]
djlogs.sort(key=lambda x: os.path.getmtime(x))
retlist = []
for jlog in djlogs:
logger.debug(jlog)
with open(jlog, 'r') if not re.match('.*\.gz$', jlog) else gzip.open(jlog, 'rt') as jf:
#jl = json.load(jf)
decoder = json.JSONDecoder()
jlines = map(lambda x: decoder.raw_decode(x), jf)
#aa = decoder.raw_decode(line)
for jl in map(lambda x: x[0], jlines):
# fromisoformatで読み込むために末尾のZが邪魔なので削除
# UTCのタイムゾーンを設定してJST時刻に変換する
ts = datetime.fromisoformat(jl['timestamp'].rstrip('Z')).replace(tzinfo=timezone.utc).astimezone(tz_jst)
ts = ts.replace(microsecond=0)
if ts > st and ts < ed:
(dat, event) = (jl['ip'], jl['event'])
res0 = re.match('user logged in : (.+)$', event)
res1 = re.match('login faild.*: (.+)$', event)
event = False if res1 else True if res0 else None
if event is None:
continue
name = res1[1] if res1 else res0[1] if res0 else ''
if address is not None and address != ipv4adrset(dat):
continue
logger.debug('%s : %s - %s(%s)' % (str(ts), dat, name, event))
retlist.append(
{
'name':name,
'datetime':ts,
'address':ipv4adrset(dat),
'status':event,
'source':'django',
}
)
#print('%s : %s : %s' % (str(ts), dat, event))
return retlist
ログはdjaongo.structlogでjson形式で出力したものを対象としている
ソースプログラムを貼付けてるけど、実際はそのままでは動かない一部の公開なので誰の役にも立たないただの覚え書きなのであった。
json形式だからさっくり読めるだろうとして始めたら何かエラーになってサッパリ読めない。。何でだろうと思って先人様たちの記事をたどって調べたら、こんなもんだと上記のようにデコーダを作って1行ずつ読み込んでいくようだ。
ぇぇぇーーー。同じくpython使ってjson形式のログを掃き出してるのになんで直接読めないん??ってなった。こんど時間があったら調べてみよう
パート3と思ったけど、ちょっとdjango開発環境にて問題発生。
Ubuntuサーバー(さくらVPS)上のコンテンツを編集するのに、いろいろゴタゴタした顛末を下記に
python manage.py runserverで動作させてある程度動作検証した後に本番環境へpushするという流れにしようとした。
# settings.py で動作中のユーザー名を得る(テスト環境であればローカルユーザーになる)
RUN_USER = pwd.getpwuid(os.stat(__file__).st_uid).pw_name
# ユーザー名でApache2で動作中かどうかを判別してログのベースディレクトリを変更
LogBase = '/var/log/django' if RUN_USER == APACHE_USER else os.path.join(BASE_DIR, '.log')
# あとはログの仕様で設定する
STATIC_URL = '/static/' # これはOK
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
# ↓
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static'),
]
何ともアホらいいオチでしたが、ブラウザキャッシュは意外に見落としがち。以前のサーバー引越の時も新サーバーに以前のドメインを割り当ててても一向に変化が無くて困ったのも、結局はブラウザキャッシュが原因でした。
不正アクセスに対する対応は当サイトでは悪質な(連続で何度もログインアタック攻撃をするなど)場合、手動でblocklist(ufwの場合、/etc/ufw/before.rules)に放り込むことにしている。そのため集計対象としてはブロックリストに含まれるIPアドレスは対象外としたい。よってapacheユーザーでブロックリストを読み込む必要があるが、こちらのファイルはroot権限でしか開くことが出来ない。apacheユーザーを管理者グループに入れることも考えたが、ここはひとつ。
で、バッチリではないかと、この方針で進めることとする。
これは全く問題なしで、以前のblockset.pyより該当部分のみを抜き出したプログラムとなる。
ipアドレスを利用するクラスipv4addressはライブラリとして分離している。
表示プログラムを/usr/local/sbinなどに置きapacheユーザー(www-data)にsudo実行権限を与える
www-data ALL=(ALL) NOPASSWD:/usr/local/sbin/getblocklist.py
www-dataパスワード未設定のsu不可ユーザーなのでsudo ALLでも他のコマンドは実行出来ない。
subproccessモジュールを利用して標準出力を得るには、Popenでプロセスを起動してプロセスの標準出力を接続する必要がある。プロセスのstdoutは一行づつ取り出すイテレータとなるので、mapによりipv4adrsetのリストとして取得している。(また、なぜかプロセスの出力がバイトとなっているので、UTF-8で文字列にデコードする必要があった”x.decode('UTF-8').rstrip('\n')”)
import subprocess
get_blocklist_proccess_cmd = ['sudo','/usr/local/sbin/getblocklist.py']
# root権限でブロックリスト取得コマンドを走らせて標準入力を得る
def get_blocklist():
proc = subprocess.Popen(get_blocklist_proccess_cmd, stdout=subprocess.PIPE)
bipset = list(map(lambda x: ipv4adrset(x.decode('UTF-8').rstrip('\n')), proc.stdout))
return bipset
良く分かっていなかったのだけど、関数からmapのまま返すとイテレータなので関数の外にでてもプロセスが終わってないのね。。listとして全部取得してプロセスを正常に終らせておく必要がありましたとさ。
不正アクセスのログを集計してポータルの管理ページに結果を表示する
今回の場合はWEBページの認証機構へのログインアタックとする。パスワードを知っていて入って来てしまう場合は対象外。この場合はログイン履歴表示機能で様子をみることが可能とする。
その他機能追加として、直接関係は無いが
現在の所、最終的な完成形は上記のような仕様になるが、管理ページの追加なので訪問者には何も関係が無いです。その他思いついたら仕様追記する予定。
開発に関しては、djangoのプロジェクトディレクトリをgit管理とし、GitHubプライベートリポジトリ経由でsshログインユーザーにclone。VScodeで編集してテストブランチとしてpush。apacheユーザーでプロジェクトディレクトリ(テスト用仮想サーバー)にpullして動作試験。デバッグを行い完成形(公開レベルになった段階)をmasterブランチにmergeしてGitHubにpush。公開用プロジェクトディレクトリにpullして運用するという流れ。
単純にapacheユーザーのプロジェクトをVScodeのssh-remoteで編集したいという欲求のため、このような複雑は構造となってしまった。GitHubの使い方の勉強できて丁度良いか。
今年3月より行なってきたサーバー引越も先月終了。リファレンス用に稼働していた旧サーバー(marocha.marochanet.org)を今月末の契約終了を受けて本日停止しました。これをもって来月より新サーバー(jagha.marochanet.org)単独での運用になります。2013年7月から稼働してきた「さくらVPS(V3)2Gコース」。CentOS6にて運用開始し、2020年初頭にCentOS8にアップグレード。安定してきたところでCentOSサポート終了予定のお知らせ。それを受けてのサーバー引越でした。
さくら「VPS(V5)2GのSSD100Gコース」に無料でSSD100G追加キャンペーンに釣られての流れになるけど、Ubuntuサーバーへの引越と同時に出来て丁度良い感じでした。
まぁ、WEBサイト的には、見た目は何も変らないので変化を感じることは無いけど。。。
新サーバー(jagha):marocha君、8年間お疲れさまでした。
ちなみにmarochaはFinalFnatasyXIをプレイしていたときのメインキャラクター名(ホントはSemicolonというキャラがメインだったのだが、タルタル族の可愛さに徐々のサブキャラのmarochaで活動する機会が増え、最後にはサブがメインになってしまったというオチ)で、jaghaは現在プレイしているFinalFantasyXIVのメインキャラ名です。こちらにもmarochaというサブキャラが居るけど、今のところメインを乗っ取る気配は無さそうだ。。。
チュートリアルを使用したdjangoの勉強と並行して、djangoで構成している本サイトのポータルページもある程度のセキュリティー対策が急がれる。djangoを素で使用しているサイトは少ないようでwordpressのようにBOTによる攻撃はまだ見られない。何らかのCMSを使用しているのを見越して適当なURLをぶっ込んでくるBOTは404で弾けるのであまり問題にならないが、ごくたまーに、しつこくadminでログインしようとする輩が現れるようだ。
このWordpressのサイトでも結構多かったので(普通に見に来てくれる人は殆ど居ないのにwww)、User Login Historyというプラグインを入れている。ここもたまに100回以上のadminログイン試行をしてくる輩がいるので、このログを利用してIPを特定しblockset.pyで手動だけどお引き取り願うことにしている。
同じような仕組みをdjangoのポータルページにも仕掛けようと勉強がてら色々と調べたところ、ログイン用の認証バックエンドという仕組みが利用できそうだということが分かった。デフォルトの<project>/setting.pyには明示的に定義はされていないが(django.conf.global_settings にデフォルト定義)、AUTHENTICATION_BACKENDSという配列がありここのカスタムや追加の認証バックエンドを追加出来る(<project>/settings にて再定義)
デフォルトでは’django.contorib.auth.backends.ModelBackend’が一つ定義されているので、こちらを継承カスタマイズして認証結果をログ出力できるようにする方針とする。
class ModelBackend(BaseBackend):
"""
Authenticates against settings.AUTH_USER_MODEL.
"""
def authenticate(self, request, username=None, password=None, **kwargs):
if username is None:
username = kwargs.get(UserModel.USERNAME_FIELD)
if username is None or password is None:
return
try:
user = UserModel._default_manager.get_by_natural_key(username)
except UserModel.DoesNotExist:
# Run the default password hasher once to reduce the timing
# difference between an existing and a nonexistent user (#20760).
UserModel().set_password(password)
else:
if user.check_password(password) and self.user_can_authenticate(user):
return user
・・・・・・
認証判定にはメソッドauthenticateが機能しており、認証OKであればusernameを、NGであればNoneを返す関数であるため、クラス継承により下記のようにメソッドをオーバーライドして再定義する
from django.contrib.auth.backends import ModelBackend
from logging import getLogger # using logging module
class ModelLogBackend(ModelBackend):
def authenticate(self, request, username=None, password=None, **kwargs):
logger = getLogger('loginInfo') # example
res = super().authenticate(request, username, password, **kwargs)
if res is None:
logger.info('login faild, bad user: %s' % username)
else:
logger.info('user logged in : %s' % username)
return res
super()で親クラスのメゾッドに丸投げして、結果に応じてログを吐き出す機構を追加。継承したクラスを新たなバックエンドとして<project>/settings.pyに定義する。
# Authntication backend
AUTHENTICATION_BACKENDS = [
'<project>.backends.ModelLogBackend'
]
<project>はdjangoのプロジェクト名に置き換える。
ちなみにloggerの設定は別の記事を参照して完成しておくこと。当サイトの場合は他のアクセスログの都合でstructlogを使用している(設定さえしておけばloggingと同等に使用可能)。
もともと、ポータルとしてのdjangoサイトは出来上がっていたので、この機能を付けたくてdjangoの本格勉強を始めたという流れでした。蓋を開けてみると思ったより簡単で、同時にカスタマイズ性の高さに今更ながら感動です。次はdjabngo+bootstrap(japascript)による動的サイトの実装実験を目指したいな。





